Project 4: Video Synopsis
Video synopsis is a short video summary of a long video. In this project, I created video summaries by applying a technique called tube packing. I also synthesized two videos: bullet time video and texture transfer video.
Original videos and visualizing videos as cubes
To start this project, I thought it would be useful to use a video with a distinct object moving in a dark background. I set up a camera and took video of a single light source moving in a dark room. Shown here is the original video, as well as another more challenging video of a man dancing very well on a Fall day. The part of the video of the dancing man I used was from 0:50 to 1:20.
Original videos and visualizing videos as cubes
To start this project, I thought it would be useful to use a video with a distinct object moving in a dark background. I set up a camera and took video of a single light source moving in a dark room. Shown here is the original video, as well as another more challenging video of a man dancing very well on a Fall day. The part of the video of the dancing man I used was from 0:50 to 1:20.
To shorten these videos by tube packing, it helps to first rearrange the video in a matrix to form spacetime movies. Usually videos are stored as:
[nPy , nPx , rgb, numFrames] = size (video)
where nPy is the number of pixels in the vertical dimension of the frame, nPx is the number of pixels in the horizontal dimension of the frame, rgb is the red green blue channels of the frame, and numFrames are the number of frames. To watch the video, one displays one frame at a time. Instead we could make a spacetime frame, where one dimension is spatial and the other dimension is time. The matrix would then become either:
[nPy , numFrames , rgb, nPx] = size (video2)
OR
[nPx , numFrames , rgb, nPy] = size (video3)
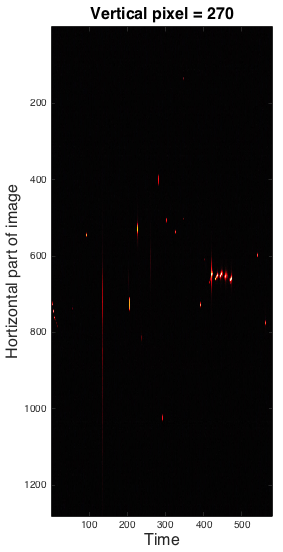
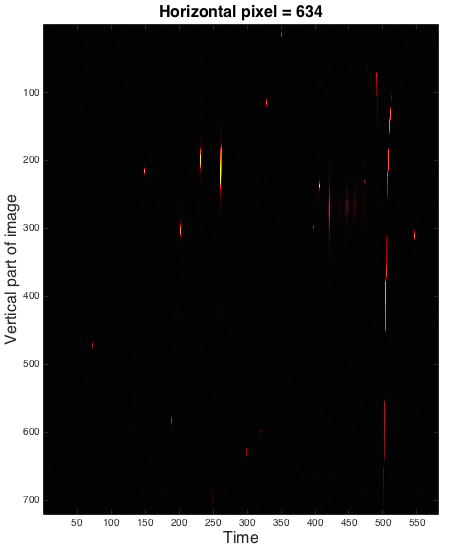
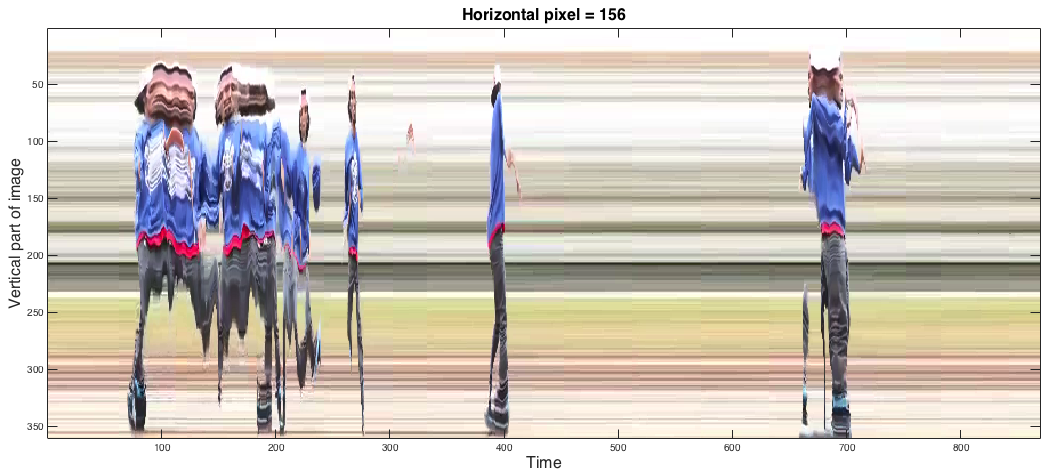
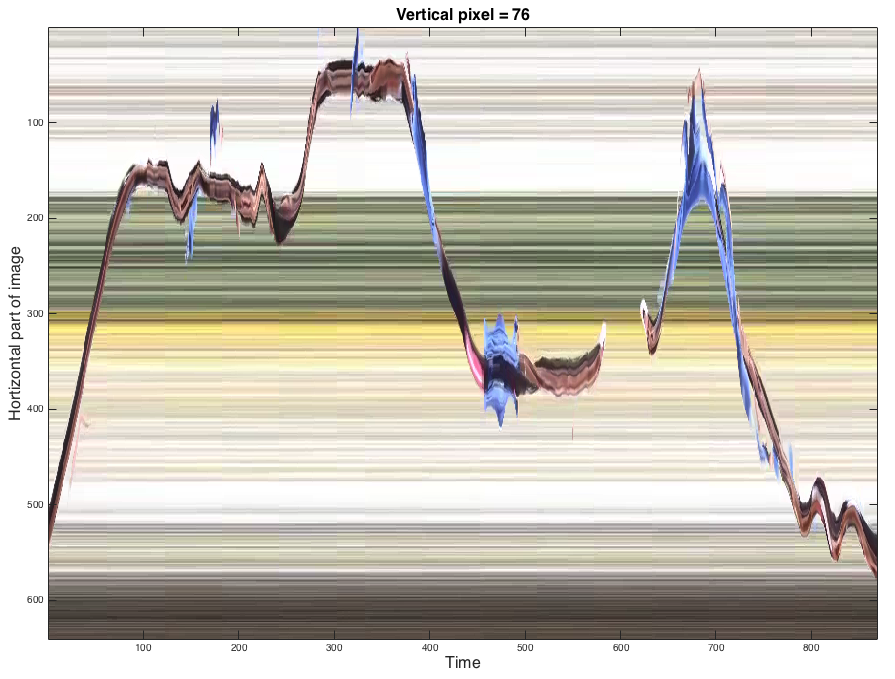
Here are some example screen shots of spacetime frames. At the end of this page there are also some videos of these spacetime frames evolving through space that are incredibly trippy. This is sort of how a Tralfamadore perceives the universe. In the frames of the man dancing, the long horizontal streaks through time are spaces that remain the same over the duration of the video.
[nPy , nPx , rgb, numFrames] = size (video)
where nPy is the number of pixels in the vertical dimension of the frame, nPx is the number of pixels in the horizontal dimension of the frame, rgb is the red green blue channels of the frame, and numFrames are the number of frames. To watch the video, one displays one frame at a time. Instead we could make a spacetime frame, where one dimension is spatial and the other dimension is time. The matrix would then become either:
[nPy , numFrames , rgb, nPx] = size (video2)
OR
[nPx , numFrames , rgb, nPy] = size (video3)
Here are some example screen shots of spacetime frames. At the end of this page there are also some videos of these spacetime frames evolving through space that are incredibly trippy. This is sort of how a Tralfamadore perceives the universe. In the frames of the man dancing, the long horizontal streaks through time are spaces that remain the same over the duration of the video.
|
|
|
Creating tube mask
Tube packing starts by first identifying the background of the video by taking the median frame. Amazing. The man disappears because at each pixel most the time there is only the background. For the red light video, the background is a black frame (omitted because that is boring). With the background known, we now have to create a tube of any moving objects in the video (i.e. what is different than the background). For each frame, I found the difference between the background and the frame using the function "imabsdiff." The mask was cleaned up by using imdilate to fill in gaps, bwareopen to remove really small segments, and imfilter to smooth the image. |

Median image of video clip. The man vanishes.
|

Frame before mask
|

Frame after applying mask. Could be cleaner.
|
I then added the masks over all vertical pixels to form a spacetime tube. To do the video synopsis, I want to cut up the video and arrange so that there is no overlapping spacetime tubes. For example, I want to find parts of the video that the man is dancing in different locations or that the light is moving in different positions. The spacetime tube was cut up, and then I found the number of overlapping pixels. If there are a lot of overlapping pixels, then that is not a good place to have two spacetime tubes. It is like time traveling. You don't want the man to be dancing in the same exact place at the same time or else terrible things will happen. The algorithm slides sections of the tube over the spacetime frame to determine the best place to put the tube. My tube stitching algorithm is not completely automatic yet. Notice that I removed some parts of movie where the man quickly moves to his left or right.
These first examples also only look at the spacetime tube summed in one of the spatial dimensions. This worked for the man dancing because his body exists across most of the vertical part of frame. For this algorithm to be more robust, you have to consider the spacetime tube going through both spatial dimensions.
These first examples also only look at the spacetime tube summed in one of the spatial dimensions. This worked for the man dancing because his body exists across most of the vertical part of frame. For this algorithm to be more robust, you have to consider the spacetime tube going through both spatial dimensions.
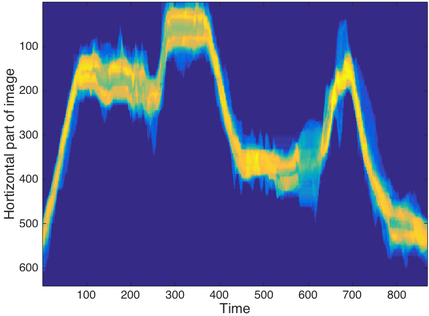
Space time tube for video of man dancing
|

Space time tube after stitching (man dancing)
|
Lastly, the video is synthesized by overlaying the videos using the mask created to make the spacetime tubes. The overlay could be improved by using Poisson blending.
Video synopsis results
Another light in the dark example. Here my friend Matt was moving a green light. To be clear, the original video has only a single red light and single green light.
Here is an example of fish in a tank - no synopsis (original video)
Lots of fish in tank after video synopsis - sorta works
Bullet time video and texture transfer
For the last part of this project, I created smeared spacetime videos (bullet-time videos), and then transferred texture onto the video (texture video). The object was masked out as described in the previous section. New frames were then created as a summation of some number of frames (as selected by used). A decreasing weight was multiplied by the image before adding to the frame so this there was some memory of movement in each frame. I used an exponential weighting function to control the effect. Here is an example with a flock of birds. Sorry quality isn't the best.
It looks like my texture video is going to take a lot of time. So it may not be posted in time for due date.
Trippy space time videos of the dancer in the fall